


Disclaimer: I gave a talk of the same title at Kubernetes Forum Delhi. You may watch the video on YouTube if you prefer that. Additionally this post also serves as a reference for the commands used in the demos.
I have been programming for almost six years now and have used containers for nearly the entirety of that time. Being a programmer, curiosity got the better of me and I started asking myself the question: what is a container? One of the answers were along the lines of the following:
“Oh they’re like virtual machines but only that they do not have their own kernel and share the host’s kernel.”
This led me to believe for a long time that containers are a lighter form of virtual machines. And they felt like magic to me. Only when I started digging into the internals of a container I realized that this quote felt very true:
Any sufficiently advanced technology is indistinguishable from magic.
— Sir Arthur Charles Clarke, author of 2001: A Space Odyssey
And I have always tried to find a way of explaining things that look like the following at first or second glance:
![]()
And see if they can be explained in a much easier way:
![]()
And the first thing I learned is that, there is really no such things as a container at all. And I found that what we know as a container, is made up of two Linux primitives:
- Namespaces
- Control groups (cgroups)
Before we look into what they are and how they help form the abstraction known as a container, it is important to understand how new processes are created and managed in Linux. Let us take a look at the following diagram:
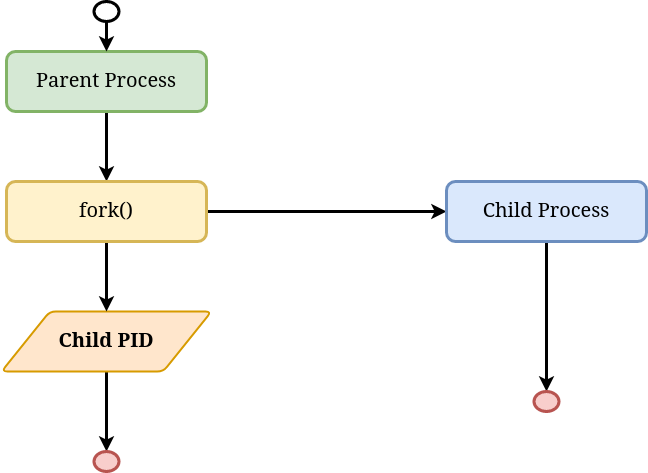
In the above diagram, the parent process can be thought of as an active shell session, and the child process can be thought of as any command being run in the shell, for eg: ls, pwd. Now, when a new command is run, a new process is created. This is done by the parent process by making a call to the function fork. While it creates a new and independent process, it returns the process ID (PID) of the child process to the parent process that invoked the function fork. And in time, both the parent and the child can continue to execute their tasks and terminate. The child PID is important for the parent to keep track of the newly created process. We will come back to this later in this blog post. If you’re interested to go deeper into the semantics of fork, I wrote a more detailed blog post in the past describing this and how to do that with code.
Namespaces
So now that you have an idea about how new processes are created in Linux, let us try and understand what namespaces help us achieve.
Namespaces are an isolation primitive that helps us to isolate various types of resources. In Linux, it is possible to do this for seven different type of resources at the moment. They are, in no specific order:
- Network namespace
- Mount
- UTS or Hostname namespace
- Process ID or PID namespace
- Inter process communication or IPC namespace
- cgroup namespace
- User namespace
I won’t go into detail about what each of them does in this post, as there is already a lot of literature on that and the man pages are possibly the best resource for them. Instead, I will try to explain network namespaces in this post and see how it helps us to isolate network resources. But before that, it is important to note that by default each of these namespaces already exists in the system and are called the host namespaces or the default namespaces. For example, the default network namespace in a system contains network interface cards for WIFI and / or the ethernet port if there’s one.
All the infromation about a process is contained under procfs, which is typifcally mounted on /proc. Running echo $$ will give us the PID of the currently running process:
$ echo $$
448884
And if we look inside /proc/<PID>/ns we will the list of namespaces used by that process. For example:
$ ls /proc/448884/ns -lh
total 0
lrwxrwxrwx 1 root root 0 Feb 23 19:00 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Feb 23 19:00 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Feb 23 19:00 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 root root 0 Feb 23 19:00 net -> 'net:[4026532008]'
lrwxrwxrwx 1 root root 0 Feb 23 19:00 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Feb 23 19:00 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Feb 23 19:00 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Feb 23 19:00 uts -> 'uts:[4026531838]'
For each namespace, there is a file which is a symbolic link[1] to ID of the namespace. So for the network namespace, the ID of the namespace in the above example is net:[4026532008] while 4026532008 is the inode number. For two processes in the same namespace, this number is the same.
On Linux, to create a new namespace, we can use the system call unshare. And to create a new network namespace we need to add the flag -n. So in a shell session with root privileges, we will do:
# unshare -n
We can look into the /proc/<PID>/ns directory to verify that we have indeed created a new namespace:
# ls -l /proc/$$/ns/net
lrwxrwxrwx 1 root root 0 Feb 23 18:46 /proc/447612/ns/net -> 'net:[4026533490]'
The namespace ID is different than what we see above for the host network namespace. And running the command ip link after this will only show us the loopback interface:
# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
If there are any network interfaces like the WIFI card or the ethernet port, they won’t show up at all. In fact, if we tried to run ping 127.0.0.1, something we mostly take for granted to work won’t work either:
# ping 127.0.0.1
ping: connect: Network is unreachable
But why did the above happen? Let us try to understand that.
At first we created a new network namespace. The very act isolated the network resources already in the default namespace. And the only interface available to us in this new namespace is the loopback interface. However, it does not have an IP address assigned to it yet, as a result of which ping 127.0.0.1 does not quite work. This can be verified by running:
# ip address
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Which shows that not only does this interface does not have an IP address at the moment, its state is also set to DOWN. Running the following commands would fix that:
# ip address add dev lo local 127.0.0.1/8
# ip link set lo up
At first we assigned the IP address 127.0.0.1 to that interface and set the state of the interface to UPand thus making it available to listen for incoming network packets. And now ping would work as expected:
# ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.020 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.060 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.071 ms
To understand the concept of isolation, we will go forward with trying to get this new network interface (let’s call it CHILD) to talk to the host network namespace and vice versa.
To aid our understanding, we will set the PS1 variable in this shell to something easily identifiable:
# export PS1="[netns: CHILD]# "
[netns: CHILD]#
And we will also spawn a new terminal with root access so that the shell running in it belongs to the host network namespace. Once again we will set thePS1variable to help with identifying the host namespace easily:
# export PS1="[netns: HOST]# "
[netns: HOST]#
Running the ip link command on this interface would show the currently installed network interfaces in the system. For example:
[netns: HOST]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: enp0s31f6: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
link/ether 0e:94:18:de:da:b3 brd ff:ff:ff:ff:ff:ff
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:ad:0f:83:cc brd ff:ff:ff:ff:ff:ff
11: wlp61s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DORMANT group default qlen 1000
link/ether fa:3d:a9:90:95:5d brd ff:ff:ff:ff:ff:ff
To list all the network namespaces in the system we can run:
[netns: HOST]# ip netns list
But that will produce an empty output if readers have been following along. So does that mean the command didn’t work or we did something wrong there, even though we created a new network namespace earlier? The answer to both of the questions is a no. As everything is a file in UNIX[2], the ip command looks for network namespaces in the directory /var/run/netns. And currently that directory is empty. So we will first create an empty file and then try running that command again:
[netns: HOST]# touch /var/run/netns/child
[netns: HOST]# ip netns list
Error: Peer netns reference is invalid.
Error: Peer netns reference is invalid.
child
We do see thechildnamespace in the list, but we also see an error. This exists because we have not yet mapped the shell running the new namespace to this file yet. To do that, we will bind mount the /proc/<PID>/ns/net file to the new file we created above. This can be done by executing the following in the shell running the child network namespace:
[netns: CHILD]# mount -o bind /proc/$$/ns/net /var/run/netns/child
[netns: CHILD]# ip netns list
child
And this time the command to list the network namespaces works without any errors. This means that we have associated the namespace with the ID 4026533490 to the file at /var/run/netns/child and the namespace is now persistent.
Now we need to find a way to get the host and the child network namespace to talk to each other. To do this, we will create a pair of virtual ethernet devices in the host network namespace:
[netns: HOST]# ip link add veth0 type veth peer name veth1
In this command we create a virtual ethernet device namedveth0while the other end of this pair device is called veth1. We can verify this by running:
[netns: HOST]# ip link | grep veth
35: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
36: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
At the moment, both of these devices exist in the host namespace. If we runip linkin the child network namespace, it will only show the loopback address as was the case previously:
[netns: CHILD]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
So what can we do to make one of the veth devices show up in the child namespace? To do that, we will run the following command in the host network namespace. Because that is where the veth devices currently exist:
[netns: HOST]# ip link set veth1 netns child
Here we are instructing theveth1network device to be assigned to the namespacechild. Looking atip link in this namespace will not show the veth1 device any longer:
[netns: HOST]# ip link | grep veth
36: veth0@if35: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
While on the other hand, veth1 now appears in the child network namespace:
[netns: CHILD]# ip link | grep veth
35: veth1@if36: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
We have two more steps before we can make them talk to each other, which are to assign an IP address to each vethdevice and to set the state to up. So let’s do that quickly:
[netns: HOST]# ip address add dev veth0 local 10.16.8.1/24
[netns: HOST]# ip link set veth0 up
We can verify the results of the commands with:
[netns: HOST]# ip address | grep veth -A 5
36: veth0@if35: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN group default qlen 1000
link/ether 32:c7:79:c7:e2:e0 brd ff:ff:ff:ff:ff:ff link-netns child
inet 10.16.8.1/24 scope global veth0
valid_lft forever preferred_lft forever
And the same for the child namespace:
[netns: CHILD]# ip address add dev veth1 local 10.16.8.2/24
[netns: CHILD]# ip link set veth1 up
[netns: CHILD]# ip address | grep veth -A 5
35: veth1@if36: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 5a:62:dd:40:a6:f1 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.16.8.2/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::5862:ddff:fe40:a6f1/64 scope link
valid_lft forever preferred_lft forever
Finally, we should be able to ping each other:
[netns: HOST]# ping 10.16.8.2
PING 10.16.8.2 (10.16.8.2) 56(84) bytes of data.
64 bytes from 10.16.8.2: icmp_seq=1 ttl=64 time=0.086 ms
64 bytes from 10.16.8.2: icmp_seq=2 ttl=64 time=0.099 ms
64 bytes from 10.16.8.2: icmp_seq=3 ttl=64 time=0.100 ms
[netns: CHILD]# ping 10.16.8.1
PING 10.16.8.1 (10.16.8.1) 56(84) bytes of data.
64 bytes from 10.16.8.1: icmp_seq=1 ttl=64 time=0.057 ms
64 bytes from 10.16.8.1: icmp_seq=2 ttl=64 time=0.090 ms
64 bytes from 10.16.8.1: icmp_seq=3 ttl=64 time=0.118 ms
Voila! We did it! I hope that helps with understanding namespaces better. What we did above can be best described by an image of two children talking to each other with a string telephone made up of tin cans and a long string. The children can be thought of as the namespaces, while the tin cans are analogous to the virtual ethernet devices we created and used for sending and receiving network traffic.
cgroups
Next up is cgroups. They help us in controlling the amount of the resources that a process can consume. The best examples for this are CPU and memory. And the best use case to do this is to avoid a process from accidentally using all the available CPU or memory and choking the entire system. The cgroups reside under the /sys/fs/cgroup directory. Let us take a look at the contents:
# ls /sys/fs/cgroup/ -lh
total 0
dr-xr-xr-x 5 root root 0 Feb 17 01:05 blkio
lrwxrwxrwx 1 root root 11 Feb 17 01:05 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 Feb 17 01:05 cpuacct -> cpu,cpuacct
dr-xr-xr-x 5 root root 0 Feb 17 01:05 cpu,cpuacct
dr-xr-xr-x 2 root root 0 Feb 17 01:05 cpuset
dr-xr-xr-x 5 root root 0 Feb 17 01:05 devices
dr-xr-xr-x 2 root root 0 Feb 17 01:05 freezer
dr-xr-xr-x 2 root root 0 Feb 17 01:05 hugetlb
dr-xr-xr-x 9 root root 0 Feb 20 00:24 memory
lrwxrwxrwx 1 root root 16 Feb 17 01:05 net_cls -> net_cls,net_prio
dr-xr-xr-x 2 root root 0 Feb 17 01:05 net_cls,net_prio
lrwxrwxrwx 1 root root 16 Feb 17 01:05 net_prio -> net_cls,net_prio
dr-xr-xr-x 2 root root 0 Feb 17 01:05 perf_event
dr-xr-xr-x 5 root root 0 Feb 17 01:05 pids
dr-xr-xr-x 2 root root 0 Feb 17 01:05 rdma
dr-xr-xr-x 5 root root 0 Feb 17 01:05 systemd
dr-xr-xr-x 5 root root 0 Feb 17 01:06 unified
Each directory is a resource whose usage can be controlled. To create a new cgroup, we need to create a new directory inside one of these resources. For example, if we intended to create a new cgroup to control memory usage, we would create a new directory (the name is upto us) under the /sys/fs/cgroups/memory path. So let’s do that:
# mkdir /sys/fs/cgroup/memory/child
And let us take a look inside this directory. If you’re thinking: “why bother because we just created the directory and it should be empty”, read on:
# ls -lh /sys/fs/cgroup/memory/demo/
total 0
-rw-r--r-- 1 root root 0 Feb 24 12:29 cgroup.clone_children
--w--w--w- 1 root root 0 Feb 24 12:29 cgroup.event_control
-rw-r--r-- 1 root root 0 Feb 24 12:29 cgroup.procs
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.failcnt
--w------- 1 root root 0 Feb 24 12:29 memory.force_empty
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Feb 24 12:29 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.memsw.failcnt
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.memsw.limit_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.memsw.max_usage_in_bytes
-r--r--r-- 1 root root 0 Feb 24 12:29 memory.memsw.usage_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Feb 24 12:29 memory.numa_stat
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.oom_control
---------- 1 root root 0 Feb 24 12:29 memory.pressure_level
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Feb 24 12:29 memory.stat
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.swappiness
-r--r--r-- 1 root root 0 Feb 24 12:29 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Feb 24 12:29 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Feb 24 12:29 notify_on_release
-rw-r--r-- 1 root root 0 Feb 24 12:29 tasks
Turns out operating system creates a whole bunch of files for every new directory. Let us take a look at one of the files:
# cat /sys/fs/cgroup/memory/demo/memory.limit_in_bytes
9223372036854771712
The value in this file dictates the maximum memory that a process can use if it is part of this cgroup. Let us set this value to a much smaller number, say 4MB, but in bytes:
# echo 4000000 > /sys/fs/cgroup/memory/demo/memory.limit_in_bytes
And let us look inside this file:
# cat /sys/fs/cgroup/memory/demo/memory.limit_in_bytes
3997696
While this is not exactly what we wrote into the file, it is approximately 3.99 MB. My guess is that this has something to do with memory alignment which is managed by the operating system. I haven’t researched this futher at the moment. (If you know the answer, please let me know!)
Now let us start a new process in a new hostname namespace:
# unshare -u
This starts a new shell process. Let us try to run a command, like wget, which I know needs more than 4MB memory to function:
# wget wikipedia.org
URL transformed to HTTPS due to an HSTS policy
--2020-02-24 12:36:58-- https://wikipedia.org/
Loaded CA certificate '/etc/ssl/certs/ca-certificates.crt'
Resolving wikipedia.org (wikipedia.org)... 103.102.166.224, 2001:df2:e500:ed1a::1
Connecting to wikipedia.org (wikipedia.org)|103.102.166.224|:443... connected.
HTTP request sent, awaiting response... 301 Moved Permanently
Location: https://www.wikipedia.org/ [following]
--2020-02-24 12:36:58-- https://www.wikipedia.org/
Resolving www.wikipedia.org (www.wikipedia.org)... 103.102.166.224, 2001:df2:e500:ed1a::1
Connecting to www.wikipedia.org (www.wikipedia.org)|103.102.166.224|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 76776 (75K) [text/html]
Saving to: ‘index.html’
index.html 100%[============================================>] 74.98K 362KB/s in 0.2s
2020-02-24 12:36:59 (362 KB/s) - ‘index.html’ saved [76776/76776]
Now we noticed that the command worked. That is because this process is part of the default cgroup. To make it part of the new cgroup, we need to write the PID of this process to the cgroup.procs file:
# echo $$ > /sys/fs/cgroup/memory/demo/cgroup.procs
And let us look inside the contents of this file:
# cat /sys/fs/cgroup/memory/demo/cgroup.procs
468401
468464
There seem to be two entries here. The first entry is the PID of the shell process that we wrote to the file. The other is the PID of the cat process that we run. This is because all child processes are part of the same cgroup as the parent by default. And once the process terminates, the PID is automatically removed from the file. If we run the same command again, we will still find two entries, but the second one would be different:
# cat /sys/fs/cgroup/memory/demo/cgroup.procs
468401
468464
And now let us try to run the wget command once again:
# wget wikipedia.org
URL transformed to HTTPS due to an HSTS policy
--2020-02-24 12:44:26-- https://wikipedia.org/
Killed
The process gets killed immediately because it was trying to use more memory than the cgroup it is part of currently permits. Pretty neat I’d say.
Addendum
So while namespaces and cgroups allow to isolate and control the usage of resources and form the core of the abstraction, popularly known as containers, there are two more concepts that are used for enhancing the isolation further:
- Capabilities: It limits the use of root privileges. Sometimes we need to run processes that need elevated permissions to do one thing but running it as root is a security risk because then the process can do pretty much anything with the system. To limit this, capabilities provide a way of assigning special privileges without giving system wide root privileges to a process. One example is if we need a program to be able to manage network interfaces and related operations, we can grant the program the capability
CAP_NET_ADMIN. - Seccomp: It limits the use of syscalls. To ramp down on security even further, it is possible to use them to block syscalls that can cause additional harm. For example blocking
killsyscall will prevent the processes from being able to terminate or send signals to other processes.
Recap
So whilenamespacesallow us to isolate the type of resource,cgroupshelp us to control the amount of resource usage by a process. And capabilities limit the use of root privileges by breaking down operations into different types of capabilities. Finally seccomp helps to block processes from invoking unwanted syscalls. These concepts combined together form a container, which is a nicer abstraction than having to worry about all of these at the same time.
One final note
The diagram aboutforkearlier in this post is slightly incomplete. Here is a more complete diagram:
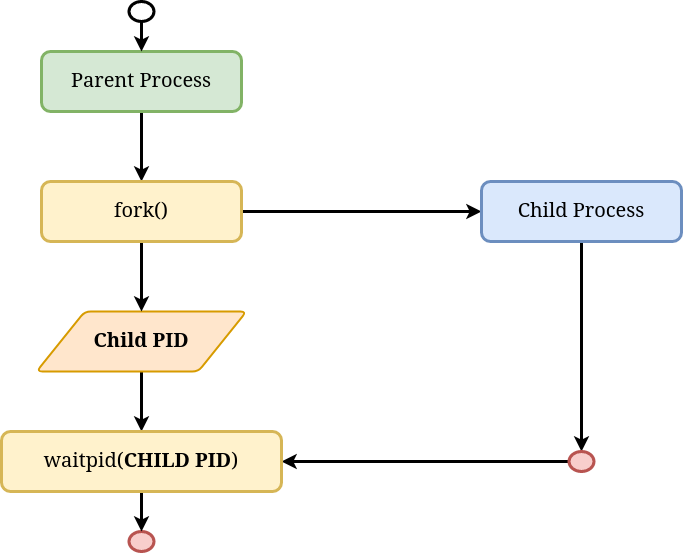
As noted earlier fork returns the child’s PID to the parent process, and it uses this PID to “wait” for the child process to finish execution. This is done by the waitpid syscall. This is important to avoid zombie processes and is known as reaping. Once a child process has terminated, it is the responsibility of the parent to ensure any resources allocated for the child process are cleaned up. In a nutshell, this is the job of a container runtime or a container engine. It spawns new conatiners or child processes and ensures the resources are cleaned up once the container has terminated.
References
- I found a lot of information about
namespacesin this amazing seven part series on lwn.net: https://lwn.net/Articles/531114/. - Julia Evans’ post on What even is a container is a brilliant guide for grasping the concepts quickly: https://jvns.ca/blog/2016/10/10/what-even-is-a-container/
- man pages for
namespaces,unshareandcgroupshave been very helpful as well and is a recommended reading.
That is all for now. I hope this post was helpful and containers don’t feel like magic anymore.
Footnotes:
[1]: Quoting the man page for namespaces: “In Linux 3.7 and earlier, these files were visible as hard links. Since Linux 3.8, they appear as symbolic links.”
[2]: https://en.wikipedia.org/wiki/Everything_is_a_file



